2021-arxiv P-tuning v1 GPT Understands, Too
Motivation
Manual discrete prompts have several drawbacks, which contain unstable performance(eg: changing a single word causes substantial drow) . To adress the problem, we propose a novel method which employs trainable continuous prompt embeddings in concatenation with discrete prompts.
Unstable performance of discrete prompts can be seen as follow:
- change a single word make large influence to prediction.
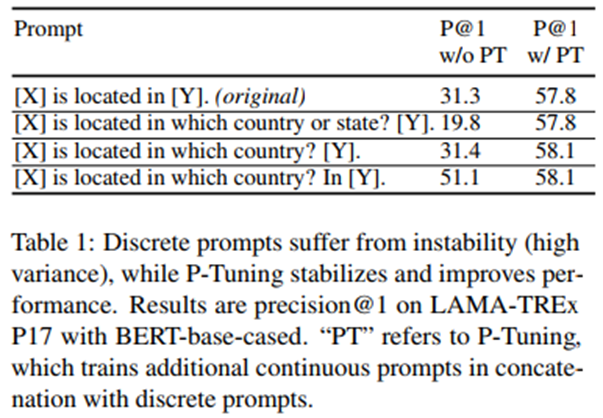
note: when the LLM is tuned, the instability can be alleviated, but performance difference is still sizeable, especially in few-shot. And recent algorithms do not well with it.
Method
Firstly, the work flow of discrete prompts is as follow:
Step1: Let M be a pretrained language model with a hidden size of h and a vocabulary size of |V|. Let {(xi, yi))}i be a labeled dataset for an NLU task, where x0:n = {x0, x1, …, xn} is an input consisting of a sequence of discrete tokens, and y ∈ Y is a label. Our goal is to estimate the conditional probability for classification fM(x) = pˆ(y|x) with parameters of M either finetuned or frozen.
- Step2: Let [Di] be a discrete prompt token. Each prompt can be described as a template T = {[D0:i], x, [D(i+1):j], y, [D(j+1):k]}
- Step3: Through the work above, the labeled data can be organized into a sequence of text tokens including x and y, and the task can be reformulated as filling in the blanks of the input text.
Eg: For the task of predicting a country’s capital (LAMA-TREx P36), a prompt could be “The capital of [INPUT] is [LABEL].” With a piece of labeled data “(Britain, London)”, the reformulated text would be “The capital of Britain is [MASK].”, where “[MASK]” should predict the given label “London”.
- The pipeline proposed in the paper and comparison with discrete prompts is as follow:
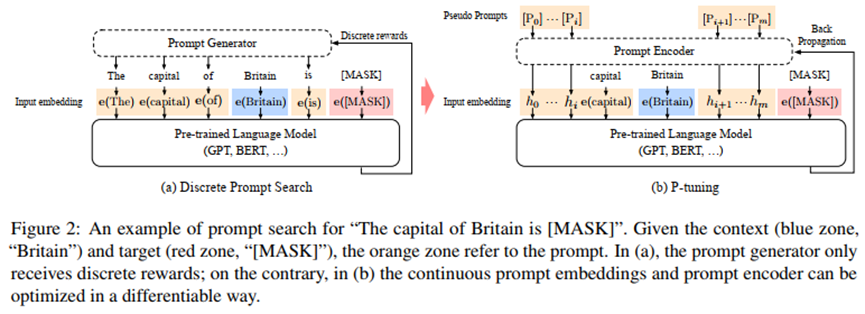
Let [Pi] be the ith continuous prompt embedding. The prompt template for P-tuning is as follows:
T = {[P0:i], x, [P(i+1):j], y, [P(j+1):k]}
P-Tuning leverages an extra embedding function f : [Pi] → hi to map the template to:
{h0, …, hi, e(x), hi+1, …, hj, e(y), hj+1, …, hk}
Finally, we update the embeddings $P_i^k$ to optimize a task loss function.
Note: For the choose of [Pi], they can be extracted from unused tokens belong to pretraining vocabulary, eg: unused 1 ~ unused99 in BERT vob.
- Prompt Encoder Network
There are three types of encoder for continuous embedding, they are LSTM, MLP and EMB. EMB means identity map and the ablation is as follow:
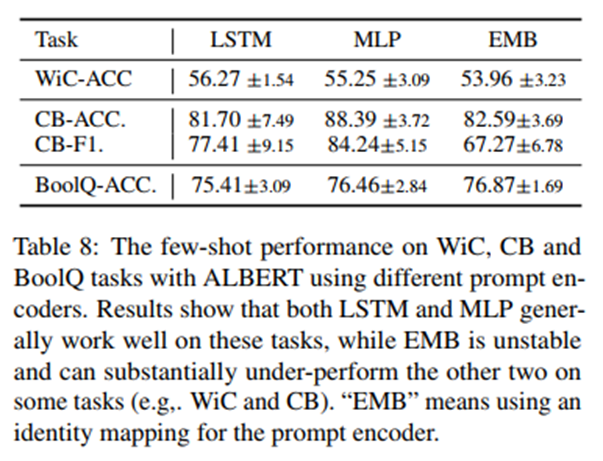
Based on the comparison above, LSTM and MLP generally works well on these tasks, and EMB can be substantially under-perform the other two on some tasks.
Results
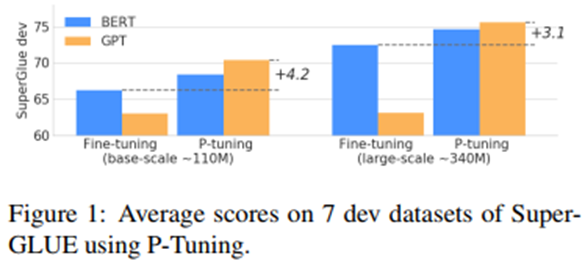
More evaluation results can be found in the paper.