2023-ECML/PKDD Improving Position Encoding of Transformers for Multivariate Time Series Classification
Motivation
The detailed study for position encoding within transformer to address MTSC problem is absent. So the paper tends to fill it in terms of Absolute Position Embedding(APE) and Relative Position Embedding(RPE). Next, authors analyse the shortcomings of them which were summarized as follows:
- APE
distance awareness property: It points to that the dot product doesn’t always decrease as the distance between two positions increases, which disappears when lower embedding dimensions, such as 64.
anisotropic phenomenon: a significant part within the embedding vectors are similar between different positions, which will do harm to classification.
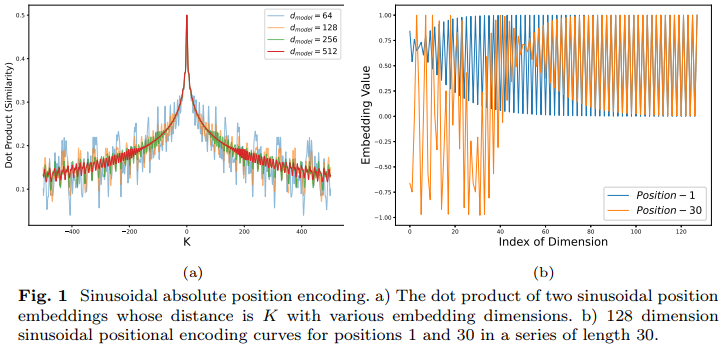
note: distance awareness property and anisotropic phenomenon can be seen above.
- RPE
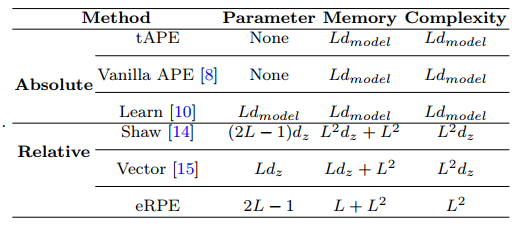
- lack of memory effiency: it requires $O({L^2}d)$ memory due to the additional relative position embedding.
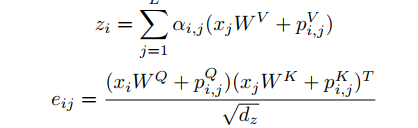
Method
The paper mainly tend to solve the problems above, and tAPE(Time Absolute Position Embedding) and eRPE(Efficient Relative Position Embedding) are proposed.
- tAPE: It takes into account the input embedding dimension and length as follows:
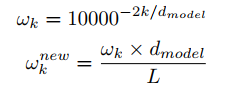
results:
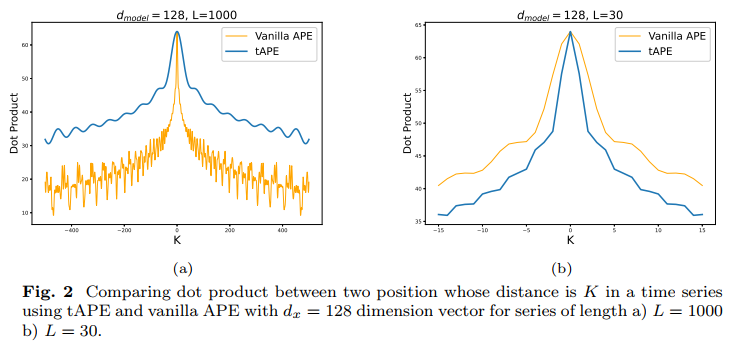
According to the fig(a) above, the distance awareness property has been alleviated, and similarity has decreased in the fig(b) which means the aniostropic problem has been addressed to a certain degree.
- eRPE
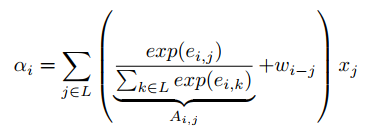
results:
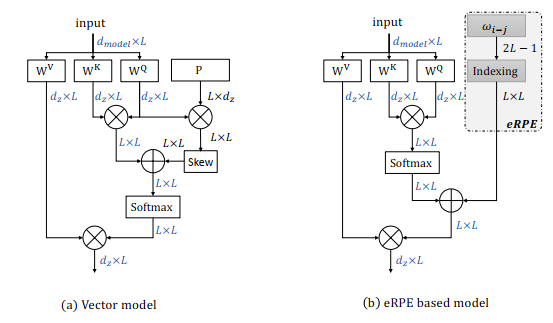
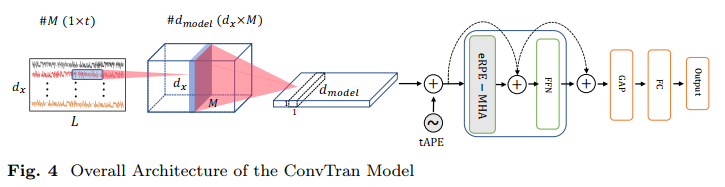
- The pipeline of ConvTran proposed:
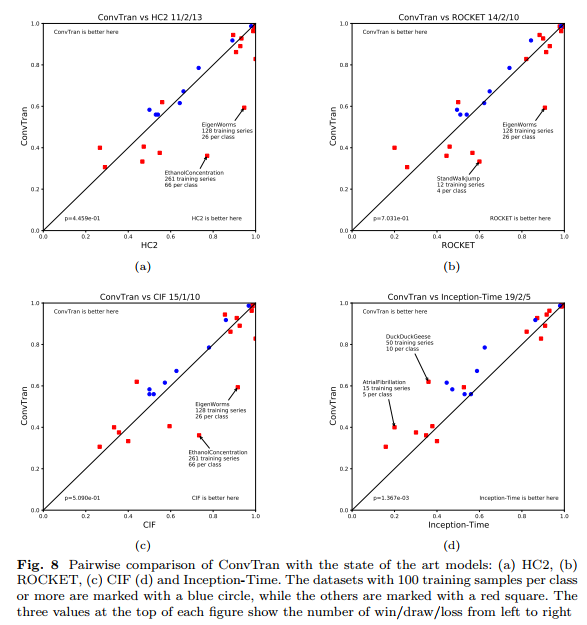
Results