2019-NIPs Unsupervised Scalable Representation Learning for Multivariate Time Series
Motivation
There exists highly variable lengths and sparse labeling in practice, to tackle the issues, a kind of unsupervised scalable representation was proposed this paper.
Method
- Backbone module uses unsupervised learning on training set(Encoder-only architecture, which contains causal Conv), the comparison between causal conv and LSTM can be seen as below:
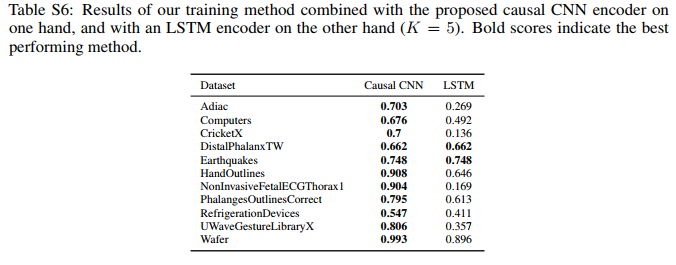
- Projection head(like: SVM) uses supervised learning on training set;
- A novel triplet loss, which samples the negative and positive pair based on the subseries from the respective sample(positive/negative sample), the relative pseudo-code is as follow:
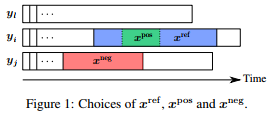

The formula of triplet loss introduced is as follow:

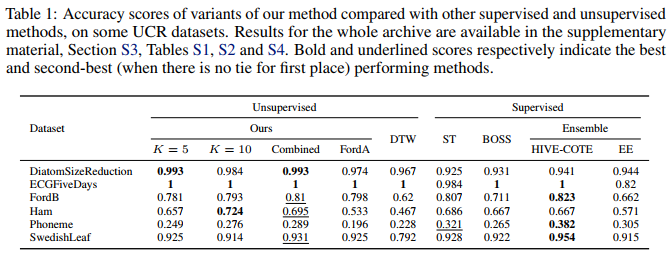
Results

2019-NIPs Unsupervised Scalable Representation Learning for Multivariate Time Series
https://firrice.github.io/posts/2024-06-26-3/