2021-KDD A TRANSFORMER-BASED FRAMEWORK FOR MULTIVARIATE TIME SERIES REPRESENTATION LEARNING
Motivation
In this paper, a transformer-based framework for unsupervised learning of multivariate time series was proposed for the first time.
Method
The overall pipeline is as follow:
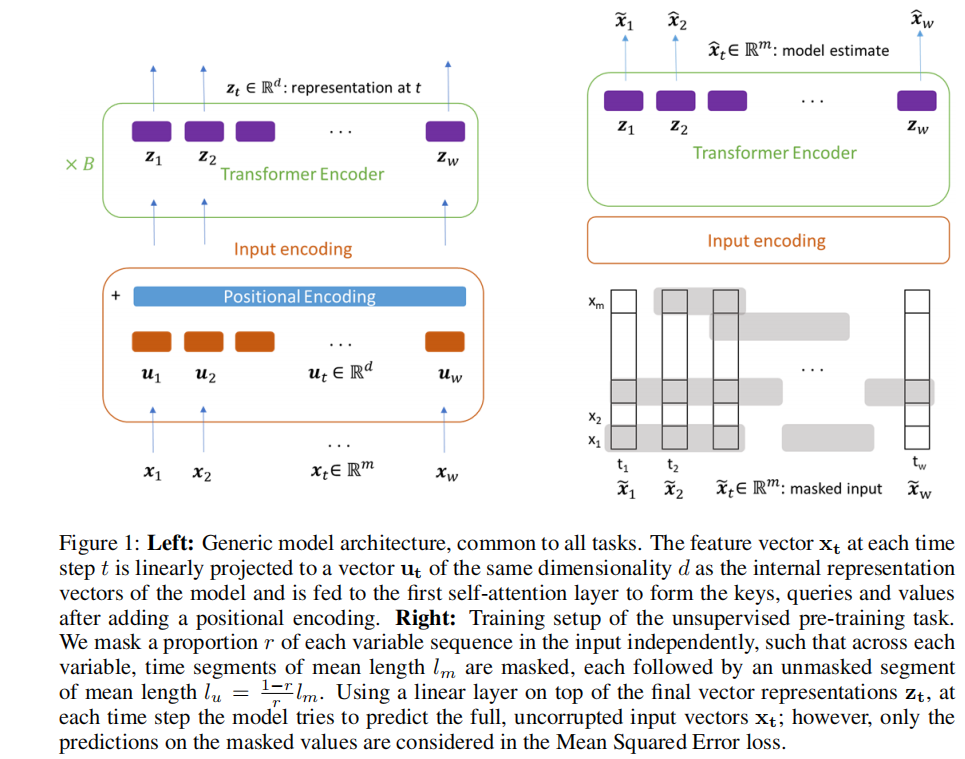
As we can see in the figure above, the pipeline consists of two phases:
(1)Pre-train
- masked input
- Pre-train a encoder-only transformer-based model to make the autoregressive objective on the traininig set.
- MSE loss was calculated pointed at masked position
(2)Fine-tune
- Add a Linear layer to project the representation learned into the output space for regression/classification tasks.
Comparison with original encoder-only model:
- normalization for each dimension across all training samples
- input was firstly linearly projected to a d-dimensional vector space, which is a bit like embedding layer in LLM
- using position embedding instead of position encoding
- padding mask: shorter samples are padded with arbitrary values, and we generate a padding mask which adds a large negative value to the attention scores
- using batch normalization rather than layer normalization
- Full-parameter finetune is better than freezon finetune
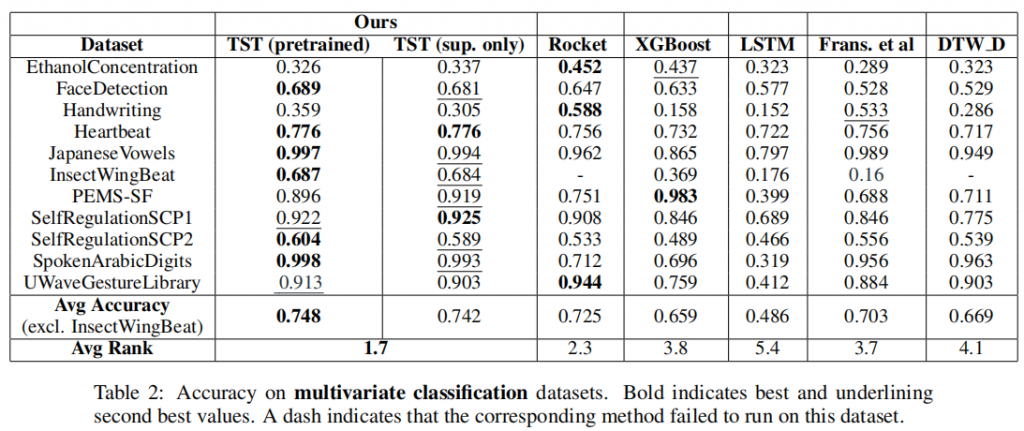
Results
2021-KDD A TRANSFORMER-BASED FRAMEWORK FOR MULTIVARIATE TIME SERIES REPRESENTATION LEARNING
https://firrice.github.io/posts/2024-06-26-5/