2022-ACL/short P-Tuning v2 Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
Motivation
In the context of NLU tasks, the prior work reveals that prompt-tuning doesn’t perform well for normal-sized pretrained model and hard sequence labeling tasks(that means difficult tasks, like: NER, etc). To address the problems, we perform a optimization version of prompt-tuning to strengthen the scalability and adaption for multi-tasks.
Method
Technically, P-tuning v2 is not conceptually novel, it can be viewed as an optimized and adapted implementation of prefix-tuning. The pipeline was depicted as blow:
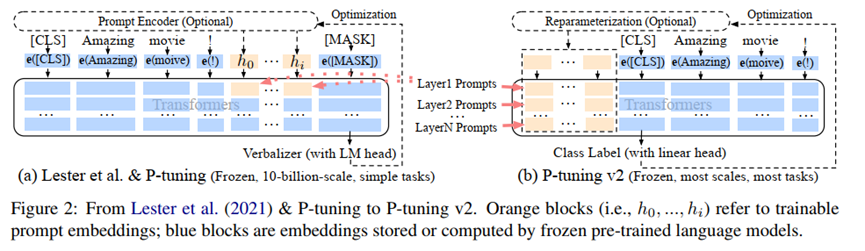
Note, there are several differences between P-tuning v2 and Prefix-tuning, which was summarized as follows:
Applied tasks: Prefix-tuning focuses on NLG tasks using only-decoder or encode-decoder, while P-tuning v2 extend to NLU and NLG tasks.
Reparameterization: we discover that its usefulness depends on tasks and datasets in the paper. And it seems like that the reparameterization(MLP head in Prefix-tuning) was removed in pratice.
Classification Head: Generally, using a language modeling head to predict verbalizers. While P-tuning v2 used random initialized classification head on top of the tokens.
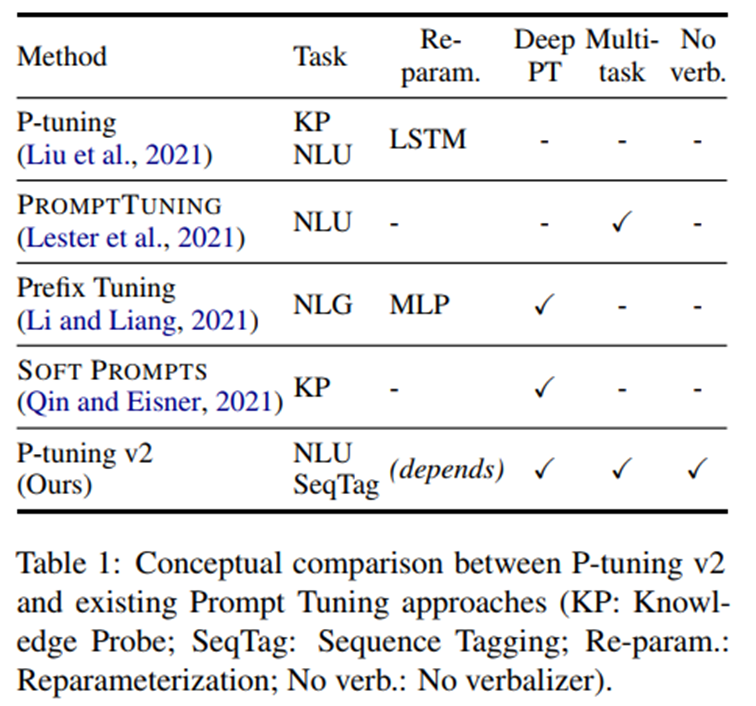
Below demonstrates the comparison between P-tuning v2 with existing Prompt-tuning approches.
Results