2024-NIPS QLoRA-Efficient Finetuning of Quantized LLMs
Motivation
A new efficient finetuning method based on quantile quantization was proposed, which realized the goal finetuning a 65B model on a single 48GB GPU, preserving full 16-bit task performance at the same time.
Method
Core concepts:
- 4-bit NormalFloat Quantization(NF4)
- Double Quantization
- Paged optimizer
4-bit NormalFloat Quantization(NF4)
The final goal
FP32 -> INT4, which the latter has a range of [-8, 7](the first bit is sign bit, and “1000” & “0000” represent the value of zero, it was agreed that “1000” points to “-8”, and “0000” points to “0”)
The overrall pipeline
(1) estimate the ${2^{\rm{k}}} + 1$ quantiles of a theoretical N(0, 1) distribution to obtain a k-bit quantile quantization data type for normal distributions;
(2) take this data type and normalize its values into the [−1, 1] range;
(3) quantize an input weight tensor by normalizing it into the [−1, 1] range through absolute maximum rescaling.
(4) quantization inference.
The detailed explaination can refer to: link1,link2
Here, we have:
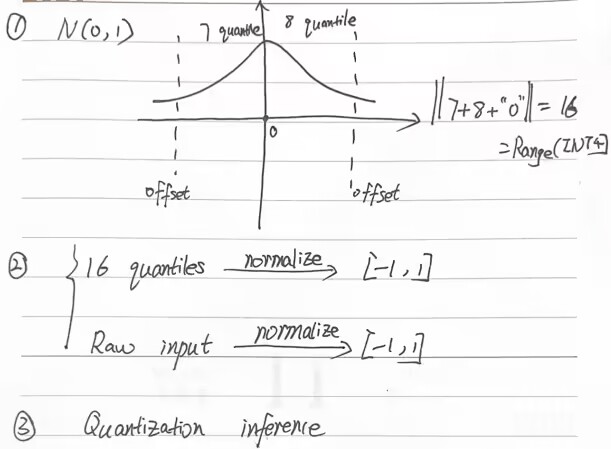
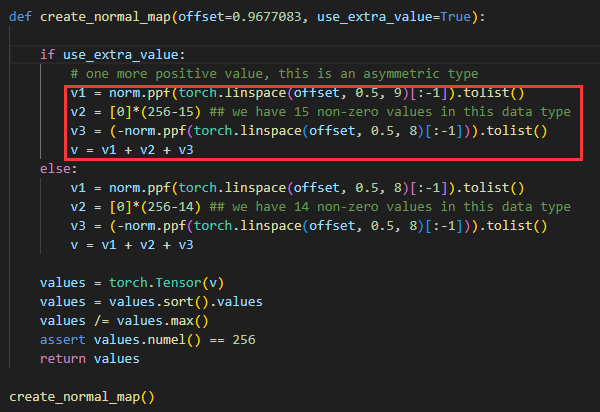
The process of getting 16 quantiles can refer to the code below:
The process of quantization inference:

Double Quantization
The core of it is to quantize the constant!

Paged optimizer
Excerpted from the raw article: “We use this feature to allocate paged memory for the optimizer states which are then automatically evicted to CPU RAM when the GPU runs out-of-memory and paged back into GPU memory when the memory is needed in the optimizer update step.”
Results
Which can refer to the raw paper.