2022-TPAMI A Survey on Deep Learning Technique for Video Segmentation
motivation
The paper forcuses on two basic lines of research containing generic object segmentation(of unknown categories)
in videos and video semantic segmentation. A github link was proposed for tracking the development
for the field, which is project(https://github.com/tfzhou/VS-Survey).
method
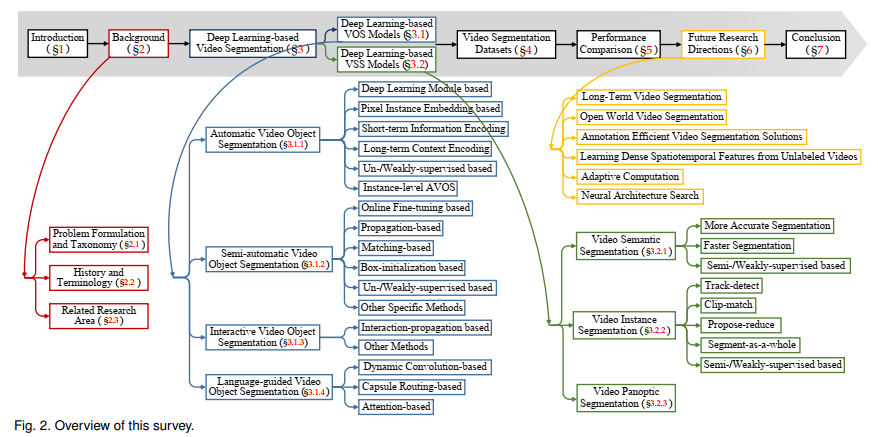
- Video segmentation tasks are mainly categorised to these taxonomies below:
- AVOS(automatic video object segmentation)
- SVOS(semi-automatic video object segmentation)
- IVOS(interative video object segmentation)
- LVOS(language-guided video object segmentation)
- VSS(video semantic segmentation)
- VIS(video instance segmentation, also termed “video multi-object segmenation”)
- VPS(video panoptic segmentation)
- The differences between VOS and VSS:
- VOS often focuses on human created media, which often have large camera motion, deformation,
and appearance changes. - VSS instead often focuses on applications like autonomous driving, which requires a good
trade off between accuracy and latency, accurate detection of small objects, model parallelization, and cross-domain
generalization ability.
- Landmark efforts in video segmentation:
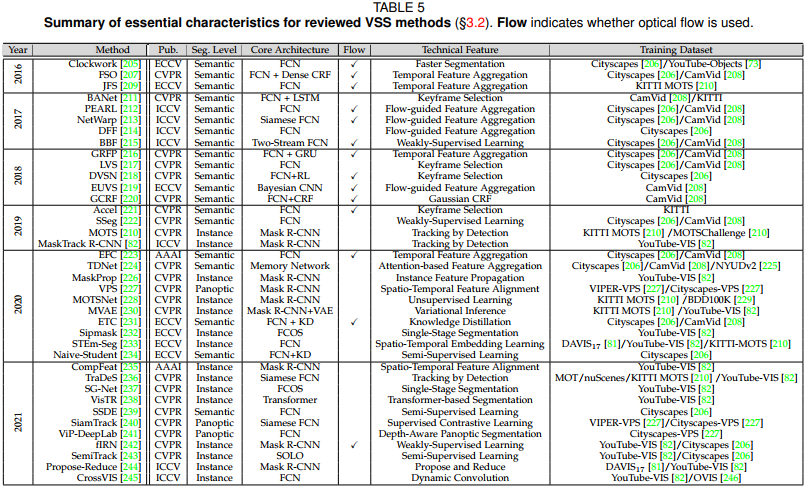
3.1 deep learning based VOS methods
3.1.1 AVOS
- deep learning moudle based methods
- Pixel Instance Embedding based methods
- End-to-end methods with Short-term Information Encoding(mainstream)
(1)RNNs;
(2)Two-stream: raw image& optical flow; - End-to-end methods with Long-term Information Encoding
- Un-/Weakly-supervised based methods(only a handful)
Instance-level AVOS methods
Overall, current instance-level AVOS models follow the classic tracking-by-detection paradigm, involving
several ad-hoc designs.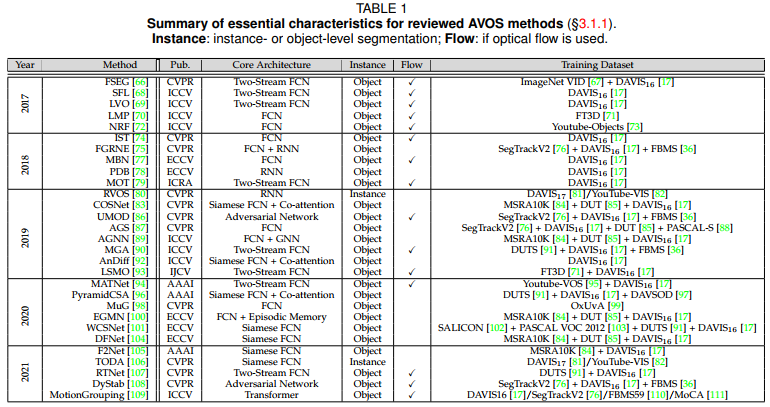
3.1.2 SVOS
Deep learning-based SVOS methods mainly focus on the first-frame mask propagation setting.- Online Fine-tuning based methods
(1)step1: offline pretraining for general object feature
(2)step2: online fine-tuning for specific object feature - Propagation-based methods
It was found to easily suffer from error accumulation due to occlusions and drifts during mask propagation - Matching-based methods
Maybe the most promising SVOS solution, which classifies each pixel’s label according to the similarity to the target object in embedding space.
STM(space-time memory) model has been a star in the domain. - Box-initialization based methods
- Un-/Weakly-supervised based methods
Other specific methods
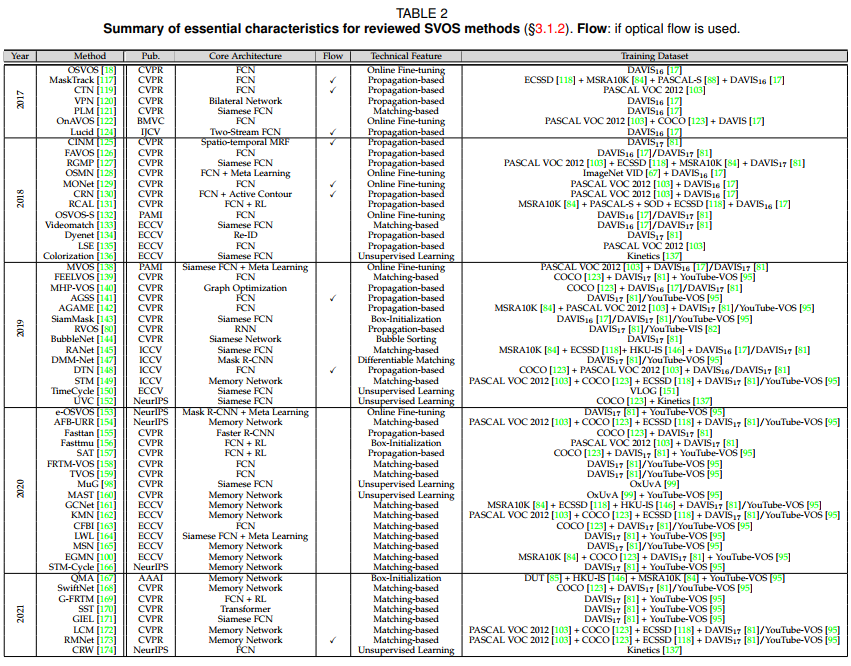
- Online Fine-tuning based methods
3.1.3 IVOS(Interactive video object segmentation)
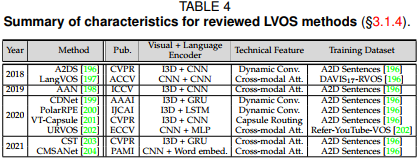
3.1.4 LVOS(Language-guided video object segmentation)
- Dynamic Convolution-based methods
- Capsule Routing-based methods
Attention-based methods
3.2 Deep learning-based VSS methods
- 3.2.1 (Instance-agnostic) video semantic segmentation
- 3.2.2 Video Instance Segmentation(VIS)
3.3.3 Video Panoptic segmenation(VPS)
- Datasets
- 4.1 AVOS/SVOS/IVOS Datasets
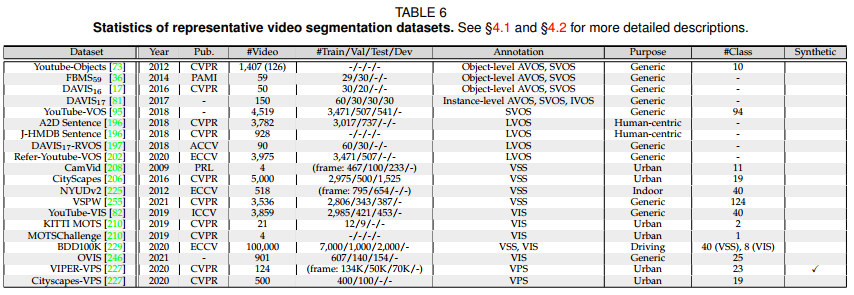
- YouTube-Objects
It is a large dataset of 1,407 videos collected from 155 web videos belonging to 10 object categories(e.g., dog, cat, plane, etc.). VOS models typically test the
generalization ability on a subset having totally 126 shots with 20,647 frames that provides coarse pixel-level fore-/background annotations on every 10th frames. - FBMS59
It consists of 59 video sequences with 13,860 frames in total. However, only 720 frames are annotated for fore-/background separation. The dataset is split into 29 and
30 sequences for training and evaluation, respectively. - DAVIS16
It has 50 videos (30 for train set and 20 for val set) with 3,455 frames in total. For each frame, in addition to high-quality fore-/background segmentation annotation,
a set of attributes (e.g., deformation, occlusion, motion blur, etc.) are also provided to highlight the main challenges. - DAVIS17
It contains 150 videos, i.e., 60/30/30/30 videos for train/val/test-dev/test-challenge sets. Its train and val sets are extended from the respective sets in DAVIS16. There
are 10,459 frames in total. DAVIS17 provides instance-level annotations to support SVOS. Then, DAVIS18 challenge provides scribble annotations to support IVOS. Moreover, as
the original annotations of DAVIS17 are biased towards the SVOS scenario, DAVIS19 challenge re-annotates val and test-dev sets of DAVIS17 to support AVOS. - YouTube-VOS
It contains 150 videos, i.e., 60/30/30/30 videos for train/val/test-dev/test-challenge sets. Its train and val sets are extended from the respective sets in DAVIS16. There
are 10,459 frames in total. DAVIS17 provides instance-level annotations to support SVOS. Then, DAVIS18 challenge provides scribble annotations to support IVOS. Moreover, as
the original annotations of DAVIS17 are biased towards the SVOS scenario, DAVIS19 challenge re-annotates val and test-dev sets of DAVIS17 to support AVOS. - Remark
Youtube-Objects, FBMS59 and DAVIS16 are used for instance-agnostic AVOS and SVOS evaluation. DAVIS17 is unique in comprehensive annotations for instance-level
AVOS, SVOS as well as IVOS, but its scale is relatively small. YouTube-VOS is the largest one but only supports SVOS benchmarking. There also exist some other VOS datasets,
such as SegTrackV1 and SegTrackV2, but they were less used recently, due to the limited scale and difficulty.
- YouTube-Objects
4.2 LVOS Datasets
- A2D Sentence
- J-HMDB Sentence
- DAVIS17-RVOS
- Refer-YouTube-VOS
4.3 VSS Datasets
- CamVid
It is composed of 4 urban scene videos with 11-class pixelwise annotations. Each video is annotated every 30 frames. The annotated frames are usually grouped
into 467/100/233 for train/val/test. - CityScapes
It is a large-scale VSS dataset for street views. It has 2,975/500/1,525 snippets for train/val/ test, captured at 17FPS. Each snippet contains 30 frames,
and only the 20th frame is densely labelled with 19 semantic classes. 20,000 coarsely annotated frames are also provided. - NYUDv2
It contains 518 indoor RGB-D videos with high-quality ground-truths (every 10th video frame is labeled). There are 795 training frames and 654 testing frames
being rectified and annotated with 40-class semantic labels. - VSPW
It is a recently proposed large-scale VSS dataset. It addresses video scene parsing in the wild by considering diverse scenarios. It consists of 3,536 videos, and provides
pixel-level annotations for 124 categories at 15FPS. The train/val/test sets contain 2,806/343/387 videos with 198,244/24,502/28,887 frames, respectively. - YouTube-VIS
It is built upon YouTube-VOS with instance-level annotations. Its newest 2021 version has 3,859 videos (2,985/421/453 for train/val/test) with 40 semantic categories. It provides 232K high-quality annotations
for 8,171 unique video instances. - KITTI MOTS
It extends the 21 training sequences of KITTI tracking dataset with VIS annotations – 12 for training and 9 for validation, respectively. The dataset
contains 8,008 frames with a resolution of 375×1242, 26,899 annotated cars and 11,420 annotated pedestrians. - MOTSChallenge
It annotates 4 of 7 training sequences of MOTChallenge2017. It has 2,862 frames with 26,894 annotated pedestrians and presents many occlusion cases. - BDD100K
It is a large-scale dataset with 100K driving videos (40 seconds and 30FPS each) and supports various tasks, including VSS and VIS. For VSS, 7,000/1,000/2,000
frames are densely labelled with 40 semantic classes for train/val/test. For VIS, 90 videos with 8 semantic categories are annotated by 129K instance masks – 60 training
videos, 10 validation videos, and 20 testing videos. - OVIS
It is a new challenging VIS dataset, where object occlusions usually occur. It has 901 videos and 296K highquality instance masks for 25 semantic categories. It is split
into 607 training, 140 validation and 154 test videos. - VIPER-VPS
It re-organizes VIPER into the video panoptic format. VIPER, extracted from the GTA-V game engine, has annotations of semantic and instance segmentations for 10 thing and 13 stuff classes on 254K frames of
ego-centric driving scenes at 1080⇥1920 resolution. - Cityscapes-VPS
It is built upon CityScapes. Dense panoptic annotations for 8 thing and 11 stuff classes for 500 snippets in Cityscapes val set are provided every five
frames and temporally consistent instance ids to the thing objects are also given, leading to 3000 annotated frames in total. These videos are split into 400/100 for train/val. - Remark
CamVid, CityScapes, NYUDv2, and VSPW are built for VSS benchmarking. YouTube-VIS, OVIS, KITTI MOTS, and MOTSChallenge are VIS datasets, but the diversity of the last two are limited. BDD100K has both VSS and
VIS annotations. VIPER-VPS and Cityscapes-VPS are aware of VPS evaluation, but VIPER-VPS is a synthesized dataset.
- CamVid