2019-ICCV Video Object Segmentation using Space-Time Memory Networks
motivation
Available cues like the intermediate predictions of video frames become richer, while existing works can not utilize them effectively.
The paper resolves the issue by leveraging memory networks and learn to read relevant information from
all available sources.
method
In our framework, the past frames with object masks form an external memory, and the current frame as the query is segmented using the mask information in the memory.
The overall pipeline of “memory” was pictured below: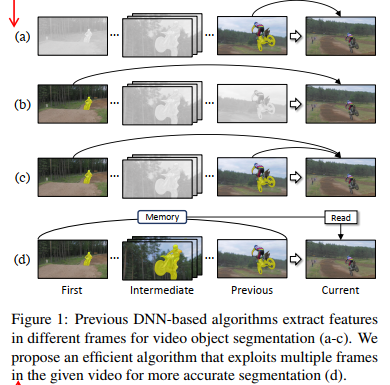
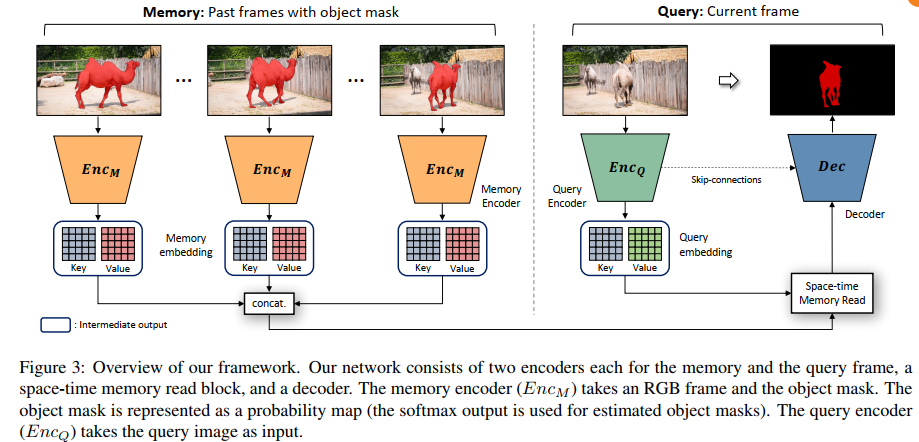
The memory nerwotk was proposed initially to address the Q&A problem in NLP, authors have make several efforts to make it suitable for the
pixel-wise labeling task, which contains:
- extend the memory dimension to the 3D spatio-temporal space.
- the space-time memory read operation was proposed to read localized information in space and time from the 3D memory.
The detailed implementation of the space-time memory read operation: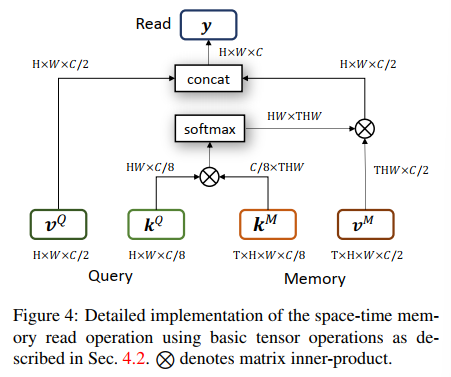
The training detailes(consists of two phases) and inference detailes:
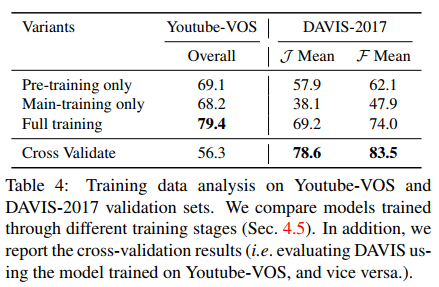
- Pre-training on images generated by applying random affine transforms to a static image, outputing the synthetic video clip that consists of three frames;
- Main-training on video, Youtube-VOS or DAVIS-2017
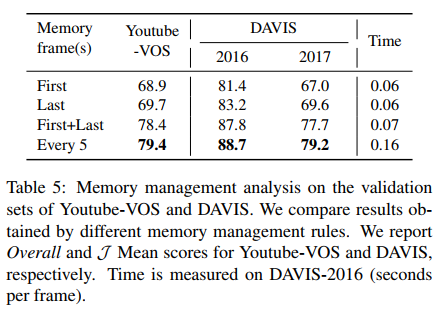
- Inference memory consists of the first, the latest frame and intermediate frames with every N frames;
note: STM is a offline method rather than online learning method, which updates the model during inferecing.
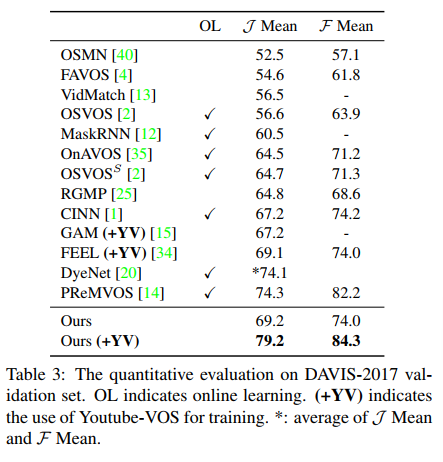
Results
The results consist of pre-training only, main-training only, full training, cross-validation, single object, multi object.