2022-ECCV XMem Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
motivation
The researchers explored the problem(“Do state-of-the-art VOS algorithm scale well?”), and the respective comparison results were depicted below: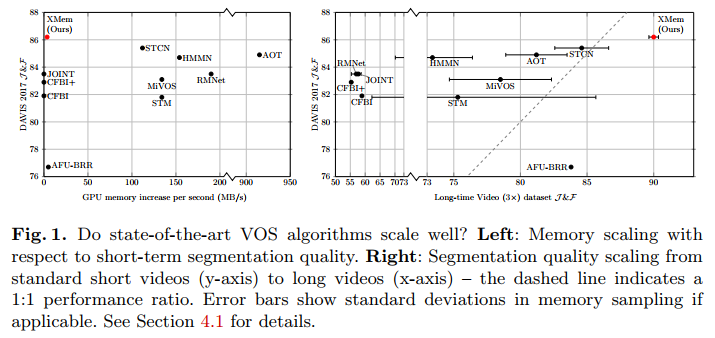
And researchers think the undesirable connection of performance and GPU memory consumption is a direct consequence of using a single feature memory type(but why?).
method
Background Knowledge: GRU, STCN, Rethink-STCN
To address the limitation above, multi-type memory mechanism inspired by the Atkinson{Shiffrin memory model was proposed,
dubbed XMem, which consists of three types of memory, sensory memory, working memory(short-term) and long-term momory.
The key feature of them was listed as below:
- sensory memory: corresponds to the hidden representation of a GRU, which is updated every frame
- working memory: To address the long-term limitation of sensory memory, it is agglomerated from a subset of historical frames and considers them equally without drifting over time.
- long-term memory: To control the size of the working memory, XMem routinely consolidates its representations into the long-term memory.
- The overview of XMem can be seen here:
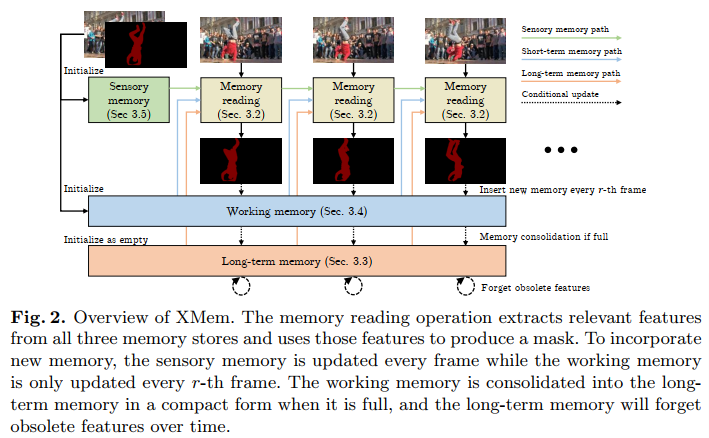
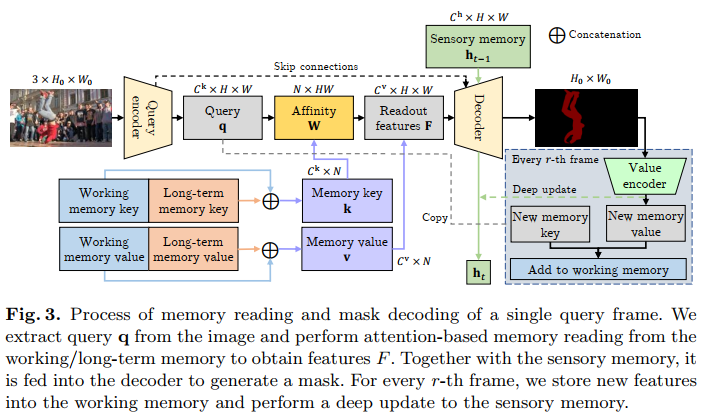
XMem consists of three end-to-end trainable convolutional networks as shown in Figure above: a query encoder that extracts query-specific image features, a decoder
that takes the output of the memory reading step to generate an object mask, and a value encoder that combines the image with the object mask to extract new
memory features.
- The detailed introduction of modules(memory update + memory reading):
- 2.1 sensory Memory update
Sensory memory is updated every frame using multi-scale features of the decoder. At every r-th frame, whenever a new working memory frame is generated, we perform a deep update. Features from the value encoder are used to refresh the sensory memory with another GRU.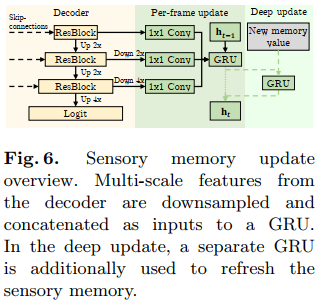
- 2.2 working Memory update
At every r-th frame, we 1) copy the query as a new key; and 2) generate a new value by feeding the image and the predicted mask into the value encoder. The new key and value are appended to the working memory and are later used in memory reading for subsequent frames. - 2.3 long-term memory update
protype selection: Concretely, we pick the top-P frequently used candidates as prototypes. “Usage” of a memory element is defined by its cumulative total affinity (probability mass) in the affinity matrix $W$, and normalized by the duration that each candidate is in the working memory.
memory potentiation: anti-aliasing filter with constructing the neighbourhood for the filtering in the high dimensional key space to alleviate the “aliasing” problem in sampling $v$ value. Concretely, for each prototype, we aggregate values from all the value candidates ${v^c}$ via a weighted average like the similar formula above: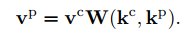
Removing Obsolete Features - 2.4 Memory Reading
$F = vW(k,q)$
$W(k,q) = softmax(S(k,q))$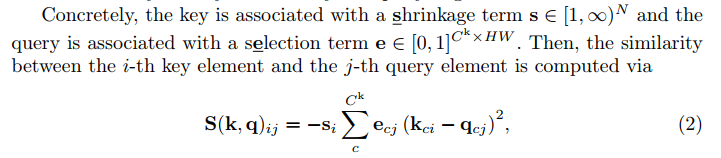
In the formula above, $s$ is shrinkage term, and $e$ is selection term. A high shrinkage represents low confidence and leads to a more local influence. Note that even low-confidence keys can have a high contribution if the query happens to coincide with it { thus avoiding the memory domination problem of the dot product.
- 2.1 sensory Memory update
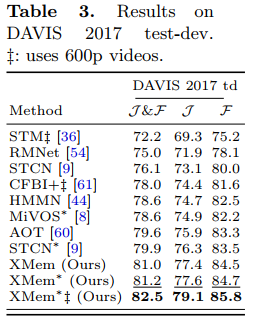
results
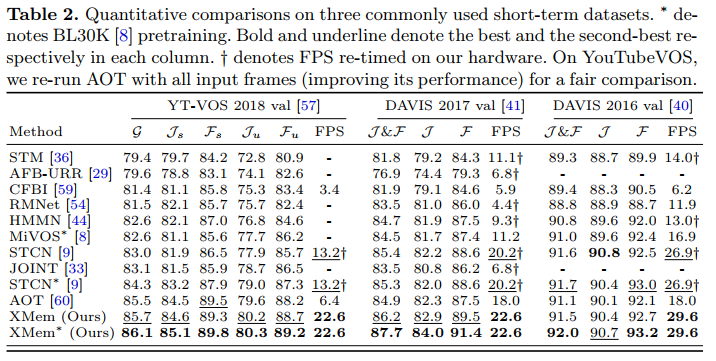
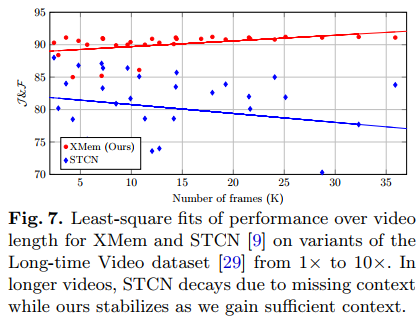
Limitations
The method sometimes fails when the target object moves too quickly or has severe motion blur as even the fastest updating sensory memory cannot catch
up. See the appendix for examples. We think a sensory memory with a large receptive field that is more powerful than our baseline instantiation could help.