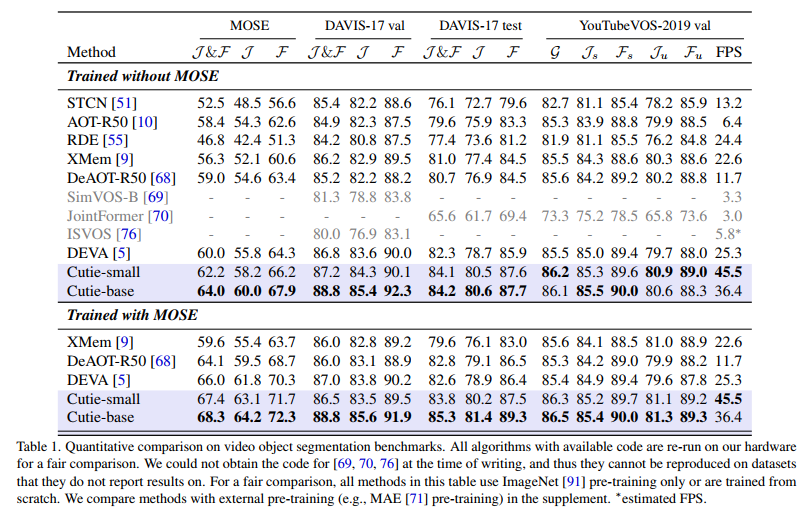
2024-CVPR Putting the Object Back into Video Object Segmentation
motivation
Recent works on VOS employ bottom-up pixel-level memory reading which struggles due to matching noise, especially in the presence of distractors, resulting
in lower performance in more challenging data.
method
Cutie method proposed in the paper performs top-down object-level memory reading by adapting a small set of object queries.
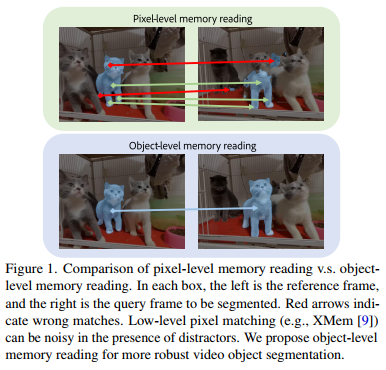
note: Pixel-level matching means mapping every query pixel independently to a linear combination of memory pixels (e.g., with an attention layer), and the comparison with object-level reading was depicted below:
The overview of Cutie was provided below:
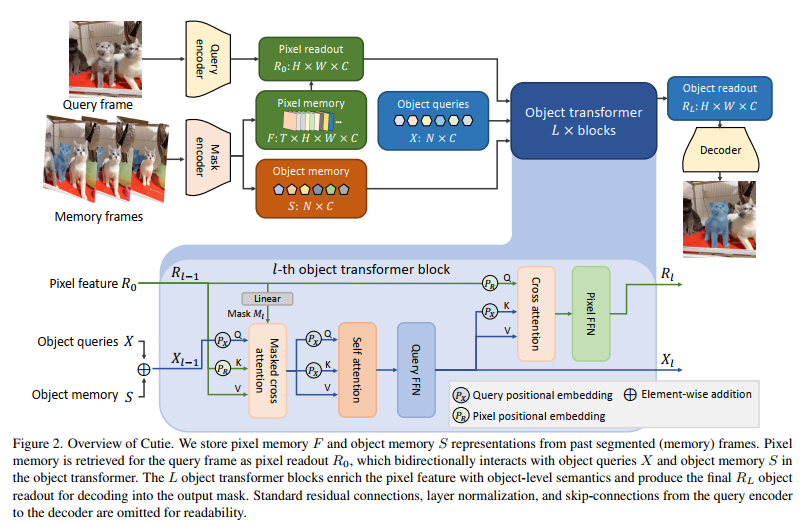
Pipeline:
- Cutie encodes segmented frames (given as input or segmented by the model) into a high-resolution pixel memory F and a high-level object memory S and stores them for segmenting future frames.
- To segment a new query frame, Cutie retrieves an initial pixel readout R0 from the pixel memory using encoded query features. This initial readout R0 is computed via low-level pixel matching and is therefore often noisy.
- We enrich it with object-level semantics by augmenting R0 with information from the object memory S and a set of object queries X through an object transformer with L transformer blocks.
- The enriched output of the object transformer, RL, or the object readout, is passed to the decoder for generating the final output mask.
The detailed sub-modules:
Within each block, we first compute masked crossattention, letting the object queries ${X_{l - 1}}$ read from the
pixel features Rl−1. The masked attention focuses half of the object queries on the foreground region while the
other half is targeted towards the background. Then, we pass the object queries into standard self-attention and feed-forward layers for object-level
reasoning. Next, we update the pixel features with a reversed cross-attention layer, putting the object semantics from object queries Xl back into pixel features Rl−1. We then pass
the pixel features into a feed-forward network while skipping the computationally expensive self-attention in a standard transformer.
- 2.1 Foreground-Background Masked Attention
Standard cross-attention with the residual path finds:
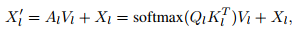
And researchers note that there are distinctly different attention patterns for different object queries – some focus on different foreground parts, some on the background, and some on distractors. So the attention masking strategy was hand-crafted as below:
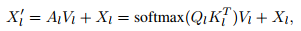

- 2.2 Positional Embedding
- 2.3 Object memory

- 2.4 Pixel Memory & Pixel reading

Training & Inference
- First, pretraining on static images, and finetune on video datasets.
- Resize the inputs such that the shorter edge has no more than 480 pixels and rescale the model’s prediction back to the original resolution.
Resulots